Agentic Commerce lässt sich in vier Phasen beschreiben, die technisch und psychologisch sehr unterschiedlich sind. Phase 1 von Agentic Commerce, die Agentic Recommendation, hat im April 2026 den deutschsprachigen Markt messbar erreicht. Dieser Artikel dokumentiert den Fall und ordnet ihn in die Taxonomie ein.
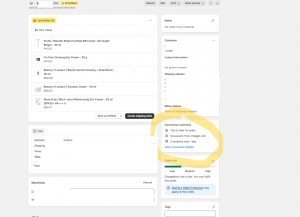
Am 20. April 2026, 10:26 Uhr, wurde in einem deutschsprachigen K-Beauty-Shop (www.koreanische-kosmetik-shop.de) eine Bestellung ausgelöst, deren erste Session eindeutig aus chatgpt.com kam. Keine Google-Suche. Keine bezahlte Anzeige. Kein Newsletter. Kein Markenkontakt. Für die LLM-Marketing-Disziplin markiert dieser Moment den Übergang von einer abstrakten These zu einem in Daten sichtbaren Fall von Agentic Recommendation.
Der 10:26-Uhr-Moment
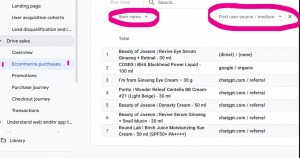
Die Faktenlage ist nüchtern – und gerade deshalb gewichtig. In einem deutschsprachigen K-Beauty-Shop landete eine Bestellung, die zwei unabhängige Tracking-Systeme, Shopify und Google Analytics 4, übereinstimmend dokumentieren:
- Der Auslöser: Die erste Session wird eindeutig als
chatgpt.com / referralausgewiesen. - Der Warenkorb: Fünf Produkte etablierter K-Beauty-Marken – Purito, Beauty of Joseon, I’m From, Round Lab – zusammengestellt als funktional vollständige Routine.
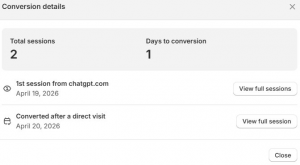
- Die Latenz: Rund 15 Stunden zwischen Erstkontakt via KI-Referral und finalem Kaufabschluss via Direktbesuch.
Der Fall beweist keinen vollautonomen Agentic Commerce. Er beweist etwas anderes, strukturell aber nicht weniger Bedeutsames: ein forensisch dokumentierter Fall von Agentic Recommendation in DACH, bei dem ein Sprachmodell nachweislich als erste Session eines Kaufprozesses fungierte – ohne jeden klassischen Werbe- oder Suchmechanismus dahinter. In der nachfolgend entwickelten Taxonomie ordnen wir ihn als Phase 1 von Agentic Commerce: Agentic Recommendation ein.
Die Beweiskette
Die Evidenz stützt sich auf zwei unabhängige Systeme, die denselben Ursprung markieren:
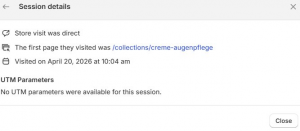
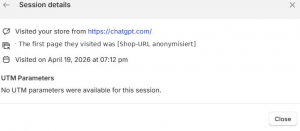
- Shopify Session Details: „Visited your store from https://chatgpt.com/” am 19. April 2026, 19:12 Uhr. Einstiegsseite: Shop-Root. Folgsession am 20. April, 10:04 Uhr, als „direct” klassifiziert, Einstieg auf einer spezifischen Kategorieseite.
- Shopify Conversion Summary: „1st session from chatgpt.com. 2 sessions over 1 day. 1st order.” Bestellzeitpunkt: 10:26 Uhr.
- Google Analytics 4, Ecommerce Purchases mit First User Source / Medium: Alle fünf Produkte der Bestellung sind unter „chatgpt.com / referral” verzeichnet.
Zwei unabhängige Systeme zeigen denselben Ursprung: eine erste Session aus chatgpt.com, keine UTM-Parameter und einen späteren Kauf der fünf Produkte. Was nicht belegbar ist: der exakte Inhalt der Konversation, in der die Empfehlung fiel. Was belegbar ist: dass diese Konversation stattfand und zu einem Kauf führte.
Eine Taxonomie des Agentic Commerce
Der Begriff Agentic Commerce wird derzeit inflationär verwendet – für Phänomene, die mechanisch sehr unterschiedlich sind. Für die Einordnung dieses Falls ist eine vierstufige Taxonomie hilfreich, die technische Mechanik und Entscheidungshoheit trennt:
| Phase | Mechanik | Entscheidung | Ausführung |
|---|---|---|---|
| Phase 0 – Traditional Commerce | Mensch sucht → klickt → kauft | Mensch | Mensch |
| Phase 1 – Agentic Recommendation | LLM empfiehlt → Mensch folgt → kauft | Mensch mit KI-Input | Mensch |
| Phase 2 – Agent-Mediated Commerce | Agent bereitet Warenkorb und Checkout vor → Mensch bestätigt | Agent schlägt vor, Mensch genehmigt | Geteilt |
| Phase 3 – Fully Agentic Commerce | Agent kauft autonom mit hinterlegter Vollmacht | Agent | Agent |
Phase 0 – Traditional Commerce
Technischer Enabler: Suchmaschinen-Algorithmus, Keyword-basierte Ranking-Logik, klassisches SEO und SEA.
Nutzer-Psychologie: Der Nutzer möchte die Entscheidungshoheit behalten. Er betrachtet die Suchmaschine als neutrale Ergebnisliste und traut seinem eigenen Urteil mehr als einer Empfehlung.
Beispiel: Jemand sucht bei Google nach „Retinol-Serum Vergleich”, liest drei Ratgeberartikel, besucht fünf Shops, entscheidet sich für einen Anbieter.
Phase 1 – Agentic Recommendation
Technischer Enabler: Retrieval-Augmented Generation (RAG), strukturierte Daten nach Schema.org, Entity-Aufbau in Trainings- und Real-Time-Indizes, Generative Engine Optimization (GEO) und Answer Engine Optimization (AEO).
Nutzer-Psychologie: Der Nutzer delegiert die kognitive Vorarbeit an ein Sprachmodell, das er als kompetenten, neutralen Gesprächspartner wahrnimmt. Die Last des Vergleichens, Sortierens und Validierens wird zurückgegeben. Der Nutzer behält bewusst die Kaufentscheidung, nicht aber die Evaluationsarbeit.
Beispiel: Unser dokumentierter Fall. Eine Nutzerin bespricht mit ChatGPT eine K-Beauty-Routine. Das Modell nennt Marken, Produkttypen und einen Shop. Die Nutzerin besucht den Shop selbst, legt die Produkte selbst in den Warenkorb, zahlt selbst. Die Empfehlung hat gewirkt, die Ausführung blieb beim Menschen.
Phase 2 – Agent-Mediated Commerce
Technischer Enabler: OpenAI Actions, Browser-Agenten wie Perplexity Personal Computer und Claude Computer Use, erste Integrationen in Shopify und Stripe.
Nutzer-Psychologie: Der Nutzer delegiert zusätzlich die operative Vorbereitung. Er will nicht mehr selbst Kategorieseiten durchklicken und Warenkörbe füllen, aber er will vor der Zahlung bestätigen. Die Kontrolle verlagert sich vom Tun zur Freigabe.
Beispiel: Ein Nutzer sagt seinem Agenten: „Bestelle mir die Routine, die wir gestern besprochen haben.” Der Agent ruft den Shop über eine API oder über einen Browser-Workflow auf, legt die Produkte in den Warenkorb, füllt die Versandadresse aus hinterlegten Daten, stoppt vor der Zahlung. Der Nutzer prüft die Übersicht, bestätigt per Tap.
Phase 3 – Fully Agentic Commerce
Technischer Enabler: Agent-Wallets, Machine-to-Machine-Payment-Protokolle, Agent-Identity-Standards, vorautorisierte Budgets mit Regelwerken („kaufe bei Lagerstand unter X nach”).
Nutzer-Psychologie: Der Nutzer delegiert vollständig. Der Kauf wird zu einer Haushaltsroutine, die der Agent verwaltet. Die Kontrolle verschiebt sich von der Einzeltransaktion zur Regelsetzung.
Beispiel: „Sorge dafür, dass meine Skincare-Routine nie ausgeht. Budget pro Monat: X. Bevorzugte Marken: Y.” Der Agent prüft Verfügbarkeit, vergleicht Preise, kauft autonom. Kein menschliches Interface, keine Bestätigung, nur eine monatliche Kostenübersicht.
Die strukturelle Verschiebung zwischen den Phasen
Die Infrastruktur für höhere Autonomie entsteht bereits: offene Commerce-Protokolle, Zahlungsstandards und Agenten-Integrationen werden parallel entwickelt, auch wenn die breite Adoption noch aussteht. Phase 1 ist die Gegenwart, die Händler heute betrifft. Phase 2 und 3 sind die Zukunftsrichtungen, auf deren Fundamente Phase-1-Akteure aufbauen werden.
Der strukturelle Einschnitt zwischen Phase 0 und Phase 1 liegt nicht darin, dass eine Maschine klickt. Er liegt darin, dass die Vorauswahl verschwunden ist, die der Nutzer früher selbst getroffen hat. Was in Phase 0 auf einer Ergebnisseite stand, entsteht in Phase 1 im Dialog – und der Nutzer folgt ihr.
Die Attribution-Lücke
Die Attribution bleibt unvollständig. In Shopify und GA4 ist chatgpt.com als Referrer sichtbar, aber ohne UTM-Parameter und ohne vollständigen Referrer-Pfad lässt sich nicht rekonstruieren, ob die Empfehlung aus der regulären ChatGPT-Oberfläche, einem Custom GPT oder einem anderen ChatGPT-Flow kam. ChatGPT setzt beim Outbound-Klick eine restriktive Referrer-Policy; UTM-Tagging liegt in der Verantwortung des Ziel-Systems oder des Linkstellers und ist in freier KI-Konversation strukturell nicht gegeben.
Damit entsteht ein neues Grundproblem des digitalen Marketings: Ein wachsender Traffic-Kanal wird im klassischen Analytics-Stack nur noch generisch als chatgpt.com / referral sichtbar. Last-Click-Attribution und UTM-basiertes Reporting, die seit Jahren das Rückgrat der Performance-Messung bilden, verlieren an Aussagekraft, sobald KI-Konversationen die Recherche-Phase übernehmen.
Warum klassische Attribution in einer Phase-1-Welt an Grenzen stößt
Klassische Attributionsmodelle – ob Last-Click, First-Click oder datengetriebene Multi-Touch-Ansätze – setzen voraus, dass alle Berührungspunkte einer Customer Journey in Tracking-Systemen sichtbar sind. Genau diese Voraussetzung erodiert in drei Punkten:
1. Die Recherche-Phase ist unsichtbar. Der Nutzer verbringt möglicherweise zwanzig Minuten in einem KI-Dialog, in dem Marken verglichen, Produkte sortiert und ein Shop ausgewählt werden. Keiner dieser Berührungspunkte taucht in GA4, Shopify oder im CRM auf. Sichtbar wird nur das Endergebnis: ein Klick, der zu einer Conversion führt.
2. Die Zuordnung zwischen Empfehlung und Kanal bleibt unscharf. Mehrere ChatGPT-Oberflächen – reguläre Web-App, Custom GPTs, Mobile App, Drittanbieter-Integrationen über API – teilen sich denselben Referrer. Media-Mix-Modelling benötigt eindeutige Kanalzuordnungen, die hier technisch nicht verlässlich gegeben sind.
3. Die Feedback-Schleife wird länger und indirekter. Optimierungsmaßnahmen auf der Händlerseite – etwa strukturierte Daten verbessern oder Produktdokumentation ausbauen – wirken sich nicht auf einen einzelnen Klick aus, sondern auf die Wahrscheinlichkeit, überhaupt in einer KI-Antwort zitiert zu werden. Diese Wirkung ist weder in Echtzeit noch kanalscharf messbar.
Neue Messkategorien zeichnen sich ab
Als Antwort auf diese Lücke zeichnen sich neue Messkategorien ab, die noch nicht standardisiert sind, aber in der Fachdiskussion Kontur gewinnen:
- Share of Model: In welchem Anteil relevanter Queries wird die eigene Marke in KI-Antworten zitiert? Die Messung erfolgt durch systematisches Abfragen definierter Prompt-Cluster über mehrere Modelle hinweg.
- Share of Voice in LLMs: Wie häufig taucht die Marke im Vergleich zu definierten Wettbewerbern in Empfehlungen auf – und in welcher Position?
- Entity Confidence Score: Wie eindeutig kann ein Modell die Marke als spezifische Entität identifizieren, ohne sie mit ähnlichen Anbietern zu verwechseln?
- Hallucination Exposure: In welchem Umfang werden über die eigenen Produkte falsche oder veraltete Aussagen generiert, und mit welcher Reichweite?
Diese Messkategorien werden in den kommenden Monaten den Kern einer neuen Teildisziplin ausmachen. Das klassische Performance-Dashboard verschwindet nicht – aber es bekommt ein zweites, ebenbürtiges Element an der Seite.
Die drei Säulen der Empfehlungsfähigkeit
Die Frage, die jeden Händler im DACH-Raum nach Sichtung eines solchen Cases beschäftigt, lautet: Was mache ich jetzt? Die Antwort liegt weniger in neuen Werbebudgets oder Tracking-Tools als in systematischer Arbeit an drei Signalebenen, die entscheiden, ob ein Sprachmodell eine Marke oder einen Shop überhaupt als Empfehlung ausspielt.
Daten-Souveränität: Die einzige Sprache, die der Agent spricht
Sprachmodelle sehen keine Hochglanzbilder. Sie sehen keine Animationen, keine Hero-Visuals, keine emotional gestalteten Landingpages. Was sie verarbeiten, sind strukturierte Daten: JSON-LD-Markup nach Schema.org, maschinenlesbare Produkt-Feeds, klare Entity-Definitionen in Meta-Tags, konsistente Preis- und Verfügbarkeitsangaben in Feeds wie Google Merchant Center.
Wer Produktdaten nur in menschenlesbarer Form bereitstellt, ist für Agenten-Infrastrukturen in weiten Teilen unsichtbar. Das betrifft nicht nur Produktdetails, sondern auch Markenbeschreibungen, Kategoriestrukturen, Inhaltsstoffangaben, Autor-Kennzeichnungen bei Ratgeber-Content. Jedes strukturierte Feld ist ein Datenpunkt, aus dem ein Modell seine Einschätzung bildet. Jedes fehlende Feld ist eine Lücke, die entweder mit Nichterwähnung oder mit einer Halluzination geschlossen wird.
Daten-Souveränität bedeutet, die Kontrolle darüber zurückzugewinnen, wie die eigene Marke maschinell gelesen wird. Wer die Struktur bereitstellt, bestimmt die Lesart. Wer es nicht tut, überlässt sie dem Modell.
Brand Consistency im LLM-Space: Consensus-Validation als neuer Standard
Sprachmodelle bauen Entitäten nicht aus einer einzigen Quelle auf. Sie aggregieren Signale über Dutzende oder Hunderte von Quellen hinweg: die eigene Website, Branchenverzeichnisse, Fachmedien, Bewertungsplattformen, Social-Media-Profile, Erwähnungen in Blogs, Reddit-Diskussionen, Wikipedia-Einträge, Pressemitteilungen, Partner-Seiten.
Entscheidend ist nicht die Zahl der Signale, sondern ihre Konsistenz. Wenn die Marke auf der Homepage anders beschrieben wird als im LinkedIn-Profil, wenn die Unternehmensbeschreibung im Impressum von der About-Seite abweicht, wenn die Produktkategorisierung in Google Shopping nicht zum Site-Navigation passt – dann entsteht keine scharfe Entität im Modell, sondern ein unscharfer Konsens. Unscharfe Entitäten werden seltener empfohlen.
Brand Consistency im LLM-Space bedeutet, Signale bewusst zu streuen und aktiv konsistent zu halten: gleiche Markenbeschreibung über alle Quellen hinweg, gleiche Kategorisierung der Kernprodukte, gleiche Tagline, gleiche Gründungsjahre und Positionierungsaussagen. Der Gewinn ist doppelt: Starke Entitäten werden empfohlen, schwache Entitäten werden ersetzt.
Die Hallucination Tax: Wenn fehlerhafte Daten zu fremden Empfehlungen werden
Wenn Daten unsauber, lückenhaft oder widersprüchlich sind, passiert nicht einfach Nichterwähnung. Es passiert Schlimmeres: Das Modell ergänzt plausible, aber falsche Informationen. Ein Produkt bekommt erfundene Eigenschaften. Eine Marke wird mit einem Wettbewerber verwechselt. Ein Shop wird mit einem Sortiment assoziiert, das er gar nicht führt.
Der Begriff Hallucination Tax beschreibt den strukturellen Schaden, der daraus entsteht. Er ist für den betroffenen Händler nicht direkt sichtbar – weder in Analytics noch im Kundenkontakt – und genau deshalb gefährlich. Der Kunde fragt das Modell, das Modell liefert eine Antwort, die Antwort empfiehlt einen Wettbewerber, dessen strukturierte Daten stimmiger wirkten. Die Transaktion findet statt, nur nicht bei der richtigen Marke.
Die Hallucination Tax ist kein theoretisches Risiko. In Studien zu Google AI Overviews wird eine Fehlerquote von rund neun Prozent beobachtet. Bei Milliarden Abfragen pro Tag bedeutet das Millionen falscher Aussagen täglich – viele davon über reale Marken, mit messbarem, aber nicht attribuierbarem Umsatzschaden.
Das Window of Opportunity
Die Struktur des beobachteten Warenkorbs – fünf spezifische Produkte als abgestimmte Routine, erworben in einem einzigen Einkaufsvorgang nach einer einzigen KI-getriebenen Session – passt zu dem Muster, das Agentic Recommendation typischerweise produziert. Ein technischer Kausalbeweis dafür, dass eine konversationelle Beratung stattfand, lässt sich ohne UTM-Daten nicht führen. Was sich belegen lässt: Die Empfehlung führte zum Klick. Der Klick führte zum Kauf.
Daraus ergeben sich drei Beobachtungen, die für Händler im DACH-Raum strategisch relevant werden:
Entity-Stärke wird zur Währung. Ein Sprachmodell empfiehlt nicht den Shop mit dem höchsten Werbebudget, sondern die Entität, die es als klar konturiert, konsistent beschrieben und thematisch valide einordnen kann. Wer in Quellen und Indizes unscharf bleibt, fällt aus dem Empfehlungs-Pool.
Datenqualität wird zur Voraussetzung von Sichtbarkeit. Maschinenlesbare Produktdaten, strukturierte Feeds und technische SEO-Hygiene sind keine Randthemen mehr, sondern Eintrittskarten in eine Konversation, die ohne sie nicht stattfindet.
Die Konsolidierung der Empfehlungslisten ist beobachtbar. Neuere Modell-Generationen zitieren im Schnitt weniger Domains pro Antwort. Wer jetzt keine stabile Entity-Position aufbaut, konkurriert später gegen Akteure, die ihre Position bereits konsolidiert haben. Der Effekt ist nicht immer laut sichtbar, sondern oft still: Wer in den Antwortsystemen nicht als verlässliche Entität auftaucht, wird seltener empfohlen – und damit seltener überhaupt in die Shortlist aufgenommen.
Ausblick: Die Agent-Economy
Der Fall vom 20. April 2026 ist eine Momentaufnahme aus Phase 1. Die strukturelle Bewegung dahinter zeigt in eine klare Richtung: Die Empfehlung wird zum dominierenden Erstkontaktformat, die Ausführung bleibt vorerst beim Menschen, und die Infrastruktur für die Delegation der Ausführung entsteht im Hintergrund.
In den kommenden 24 bis 36 Monaten werden drei parallele Entwicklungen zusammenwirken. Die Breitenadoption von Browser- und Desktop-Agenten wird Phase 2 aus der Early-Adopter-Ecke in den Mainstream bringen. Die Standardisierung von Agent-Identity und Machine-to-Machine-Payments wird Phase 3 von einer theoretischen in eine operative Möglichkeit überführen. Und die Konsolidierung der Empfehlungslisten in Sprachmodellen wird die frühen Positionsgewinne von Phase-1-Akteuren in strukturelle Vorteile verwandeln.
In dieser entstehenden Agent-Economy wird der Wert einer Marke nicht mehr primär daran gemessen, wie viel Aufmerksamkeit sie beim Menschen kauft, sondern daran, wie klar sie von Maschinen als verlässliche Entität erkannt wird. Sichtbarkeit und Empfehlungsfähigkeit sind dann keine Ergebnisse von Kampagnen mehr, sondern Eigenschaften der Dateninfrastruktur eines Unternehmens.
Phase 1 des Agentic Commerce – die Agentic Recommendation – unterscheidet sich von klassischer Suche nicht dadurch, dass die KI den Kauf ausführt, sondern dadurch, dass sie die Vorauswahl trifft. Der Mensch bestätigt nur noch, was bereits in der Konversation vorstrukturiert wurde. Dieser Satz beschreibt die Gegenwart. Die Phasen dahinter beschreiben die Zukunft, die auf ihr aufbaut.
Der 20. April 2026 war in einem konkreten Shopify-Backend der Tag, an dem diese Gegenwart messbar wurde.